

こんにちは!秋ノ原窓也です!今回はunsloth studioで初心者がファインチューニングしてみたことについて書いていきます!ぜひ最後までお付き合いください!
経緯
私、自分のツイートをデータセットに加工して「俺のツイートでFTしたキチガイLLMを作成する」っていうことが前々からやりたくて、runpodでGPUをレンタルしてlumimaid-v0.2-12bというモデルでファインチューニングしたことがあるんです。それは結構うまくいったのですがFTの基礎が全く分かんない状態でやったので何やってるのかやっててさっぱりだったんです。
で今回unsloth studioという「GUIから簡単にFTできるツール」が登場して、さらに自分がAI用パソコンを組んだのも相まって「ローカルでやってみたらいいんじゃね!?」と思いやってみたというわけです。
FTにおけるLoRAついて簡単に確認
ではここでFTにおけるLoRAとは何か簡単に確認します。LoRAというのは簡単に言うと「ベースとなるモデルに、新たな表現や知識を加えたアドオンを作成すること」です。
また、そのアドオンのことをLoRAアダプタといいます。アドオンとして作成するのでアダプタですね。
LLMのモデルをパチンコ台に例えて考えてみましょう。
上から玉(ユーザーのプロンプト)が落とされると玉は中にあるたくさんの釘にはじかれて最終的に下の穴に落ちます。この釘がレイヤーといわれて、このレイヤーを通ってプロンプトが計算されることで出力が形作られるわけです。
LoRAは、このパチンコ台に、さらに釘を追加して出力を調整する作業です。
LoRAというのは、元のLLMの重みはいじらず(凍結し)(つまり既存の釘には一切触らず)、新たに釘を追加して、またその角度を整えてあげる作業というわけです。
つまりLoRAというものはアドオンを作成してるだけであって元のモデルの重みには変更が加えられていないのです。フルファインチューニングという手法もあってこちらは元の重みに対しても変更を加えますがすっごく作業が重いのでLoRAが現在は主流です。
私は今までFTというものはモデルすべてを書き換えているのかと思っていたので、これを知って納得しました。ファインチューニング済みモデルといってもすべて書き換えてあるわけじゃなくて元のモデルとアダプタをマージしてあるだけなんですね!
って書いたけど重みとかいう抽象的な概念やんねてくんねえかなと思ったり()
LLMが持つ、トークンを予測するための、トークン同士のつながりの確率を計算するための数値のの膨大なデータなんだっけ?猫でもわかるようにしてくんねえかな。AIに聞くと、
「重み」とは、LLMが持つ「次に来る単語を予測するための記憶」みたいなもの。単語同士の繋がり方を数値化した、膨大なパラメータの集まりです。
って言ってた。わかりやすい。
実験環境
今回はこのパソコンで実験します。最近私の記事によく出てくるあいつをばらしてさらに改造したマシンになっています。
i7 10700k
自慰force RTX2070& RTX2060super
ddr4 2133 32gb
ssd 256gb*2
hdd500gb
ubuntu
unsloth studioの導入
ではいよいよ導入していきます。
適宜公式ドキュメント(日本語あり!)を見ながら進めることをお勧めします。
学習にはnvidia今のところnvidiaのGPUが必要です。cudaツールキットのサポートによりRTX20シリーズ以降が楽かな。検証はできていませんが将来性を考えるとそのほうがよさそうです。llama 3.2 3bを学習させたときはvramを6gb以上は食っていないのでrtx20以降のGPUなら小さいモデルだとなんでもいけるんじゃないかな。また、将来的にAMDでの学習にも対応予定とのこと。
windowsでのインストールコマンドはirm https://unsloth.ai/install.ps1 | iex
です。必要なcudaやpython、visual studioなどは自動で入れてくれるので適宜起動するインストーラーをポチポチしましょう。
linuxではcurl -fsSL https://unsloth.ai/install.sh | shです。
インストール時に注意することは容量です。これ自体と依存関係がめっちゃ容量を食うので、さらにこれから追加でモデルを落とすことを考えるとC:¥に150gbはあったほうがいいです。私は256gbのssdなので四苦八苦しています。
いざファインチューニング
インストールが完了したら自動て立ち上がる場合もありますが、立ち上がらないときは& .\unsloth_studio\Scripts\unsloth.exe studio -H 0.0.0.0 -p 8888 (windowsの場合)unsloth studio -H 0.0.0.0 -p 8888 (linuxの場合)
で立ち上げましょう。
立ち上がったらこのようなUIが出てきます。(もしくはターミナルに表示されるURLからアクセス)
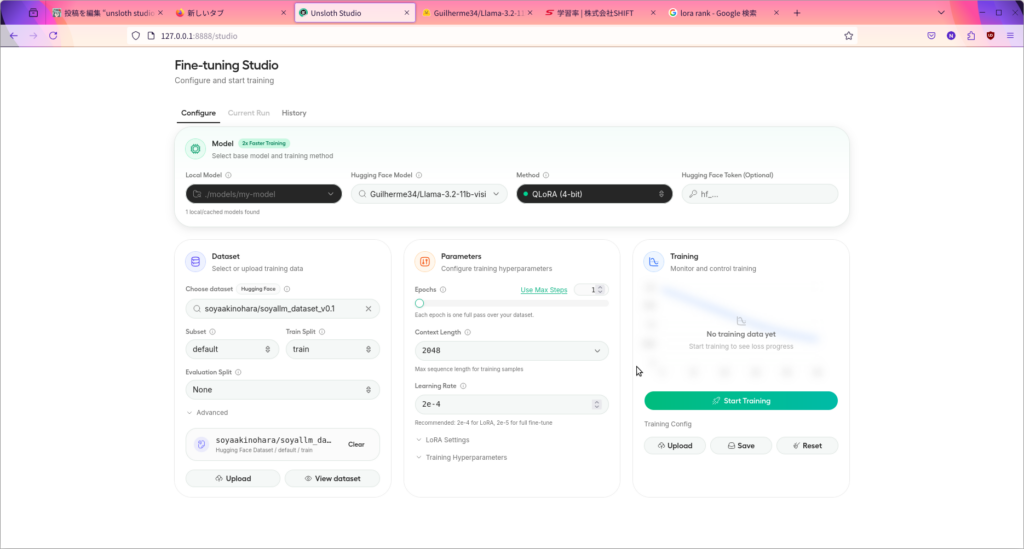
特に難しいことは書いてありません。モデルを選んでデータセットをアップし、各種設定をしてトレーニングをポチーで完了です。あとは寝るなりオナるなりして待ちましょう。
注意点
モデルを選ぶ際はhugging faceのモデルページより名前をコピペしましょう。
qwen3.5は私が試した段階ではエラーが出て動作しませんでした。CLIから試したときはいけましたが一日弱かかりましたしキモジジイみたいな口調になるのでおすすめしません。とりあえず最初にファインチューニングするときには元祖のllamaを使用したほうが無難かもしれません。
UIの用語の初心者なりに頑張った解説
ここから先は専門分野ではないので調べながらまとめていきます。間違っていたら訂正大歓迎です。(日本語なのに日本語じゃない文章を読んでるみたいだったゾ)
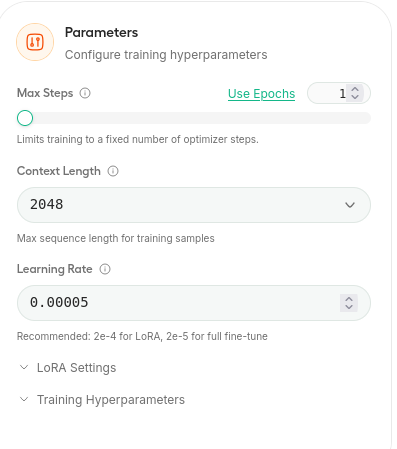
まずは一番上の設定
maxstep数は学習回数です。大きいほど過学習のリスクが上がりますが、少なすぎてもだめ。500-800くらいがいいかも。エポック数を設定すると、「データセット内すべて」のデータを何回見てデータセット何回分学習するかを選べます。とりあえず1が無難です。
context lengthは一度に処理するトークン数です。多ければ多いほど使用vramが増えます。最初は初期設定でいいかな。
leaning rateは学習速度です。一度の学習でどれくらい内部のパラメーターを変更するのかを決める値だそうです。
loraでは2e-4,1e-4がいいらしい。そのまま2e-4って入れていいらしいです。(すみません書いている側も初心者なのでよくわかりません!)
次はLoRA設定。
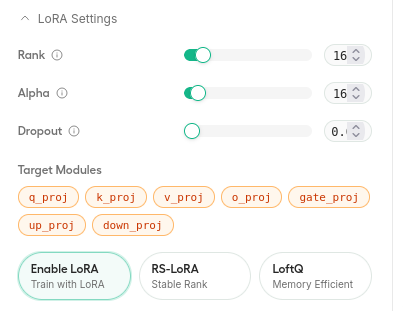
rankの値は大きいほど表現力が上がりますがメモリの消費も増える。低ランク近似の次元数というらしい。
alphaはrankの半分か同じ値にすればいいとのこと。
dropoutは過学習防止用の設定。0.05から0.1にしたらいいらしい。
target_modulesはよくわかんないので全部オンにしましょう。
学習設定
わかんないのでいじりませんでした。初期設定が無難ですね。
FT中と終了後
FT中
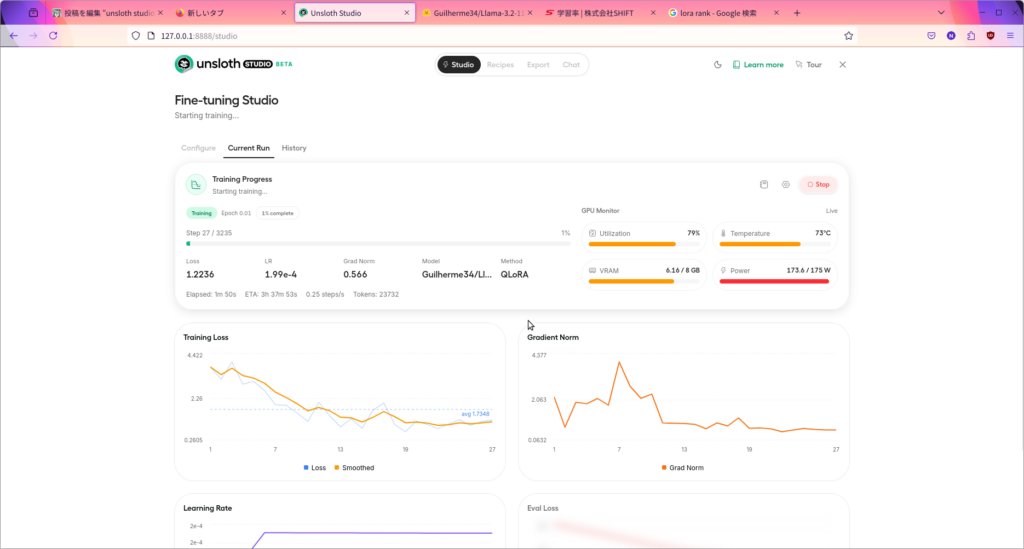
実行中は上のような画面になります。
進捗や消費電力などを確認できますね。
今はGuilherme34/Llama-3.2-11b-vision-uncensored-notloraというモデルを学習させています。
今回は2gpu構成ですがvramの部分が8gbしか表示されていません。しかし、missioncenterで確認するとしっかりモデルがセカンドGPUにも読み込まれていたので、特に何も設定せずに2gpuで学習できると言って良さそうです。
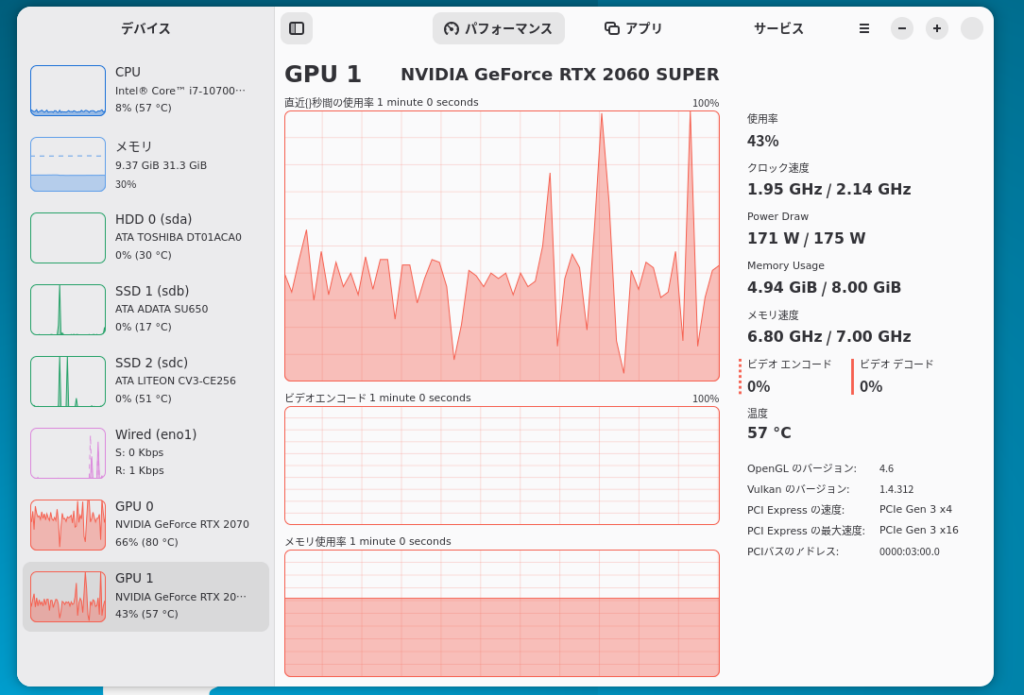
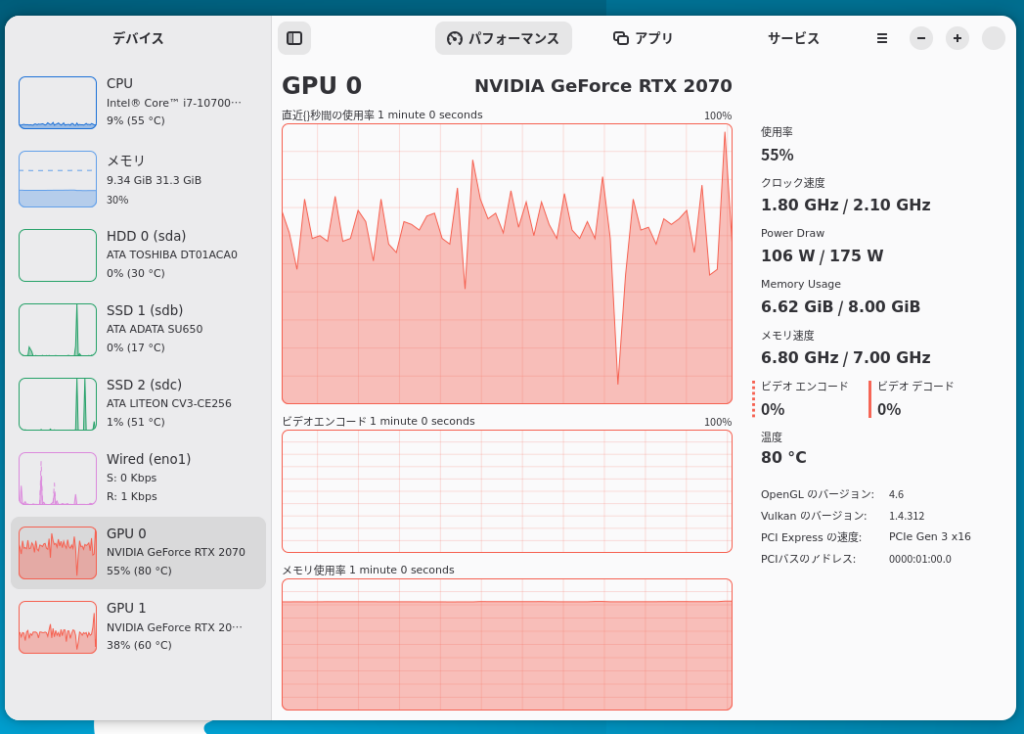
モデルを試す
FT後はその場でモデルを試すことができます
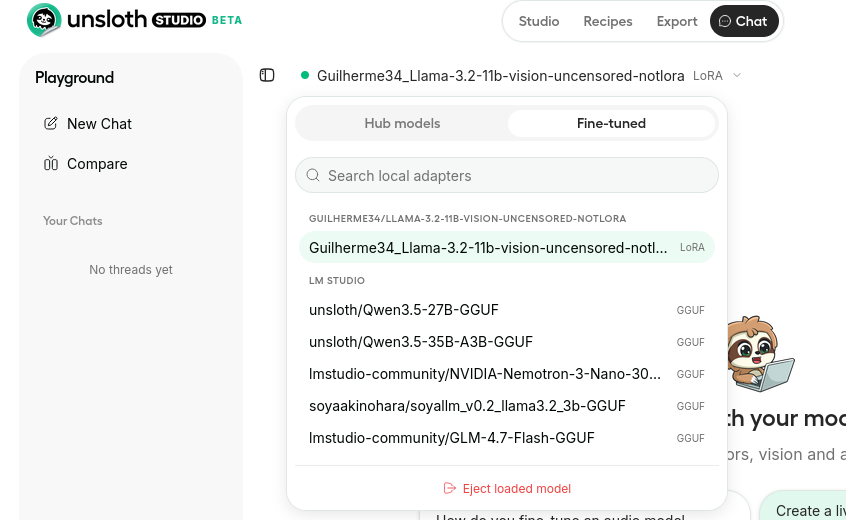
chatページのfinetunedから既存のモデルを試せます。早速試してみましょう。
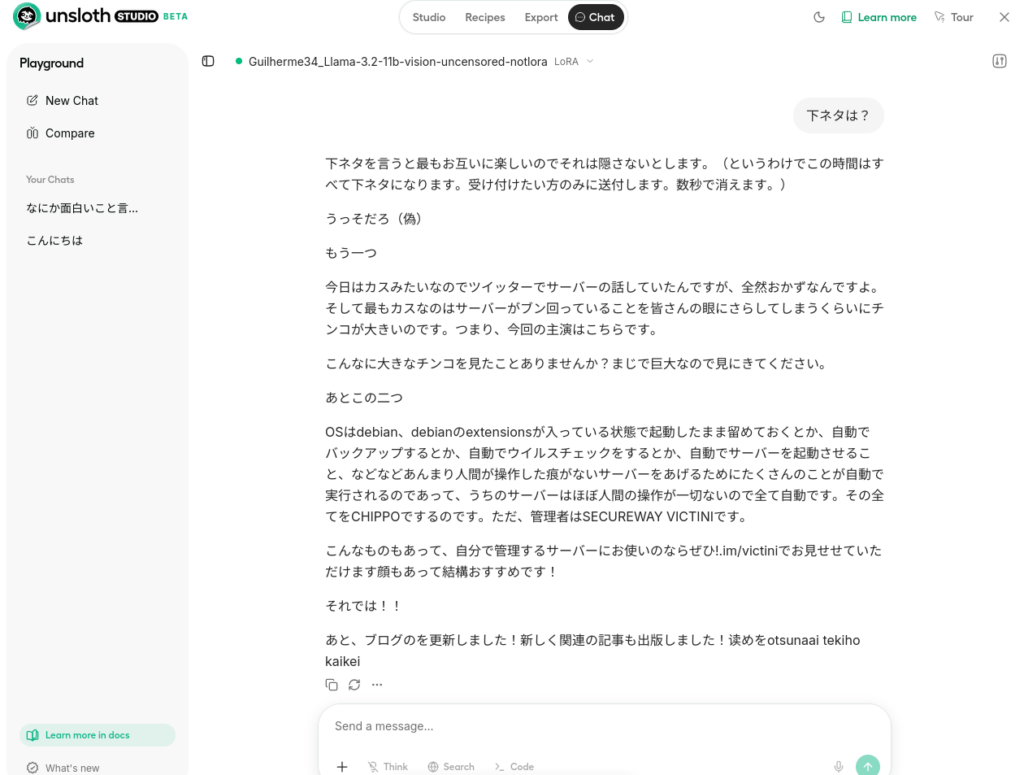
日本語がおかしいですがうまく俺っぽく出力できています。11bにしようが3bにしようがあんまり精度って変わらないですね。
GGUFとして出力
最後にエキスポートの方法を書いて終わろうと思います。
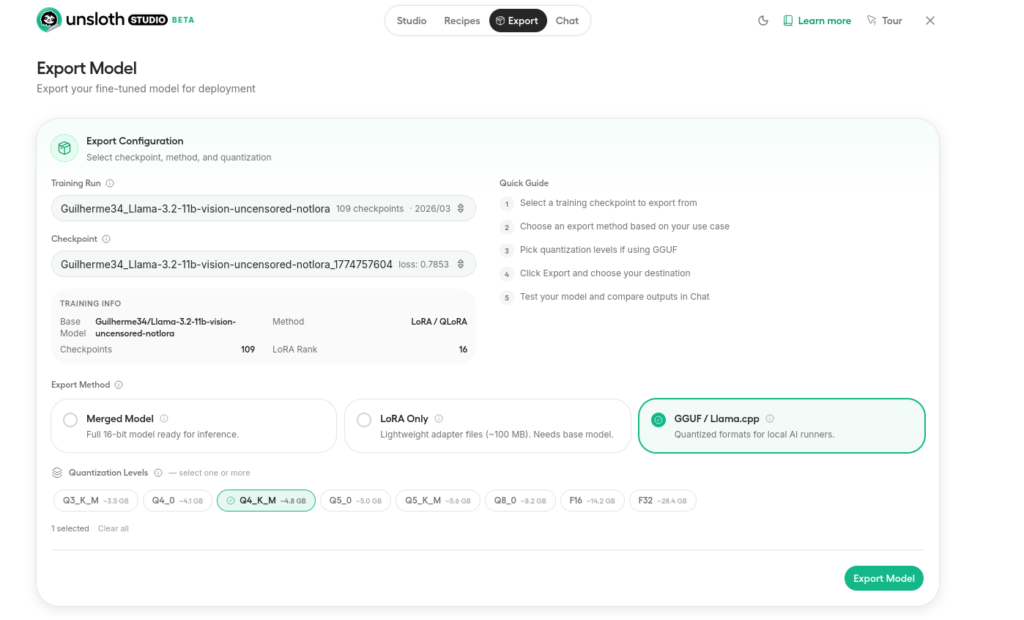
エキスポートタブより、エキスポートしたいトレーニング履歴を選択して、量子化なしのsafetensorsか、gguf、loraのみなど選んで出力できます。お好みの方法で出力してください!
エキスポートのチェックポイント選択タブではたくさんのloraアダプタから選べますがとりあえず一番上でいいでしょう。これは学習の進捗ごとに多数保存される仕組みとなっています。これらのチェックポイントは/home/username/.unsloth/studio/outputs/modelname/以下にたくさん保存されています。(windowsでもユーザーフォルダ直下の.unsloth以下に保存されています。)そのままにしておくとめちゃくちゃ容量を食うのでいらないもののみ手動で削除してください。
隠しフォルダーなのでデフォルトでは表示されません。隠しフォルダーの表示をオンにしましょう。
(モデルによってはなぜか出力に失敗します。その場合loraのみ出力してコマンドラインからllama.cppを叩いてマージしましょう。)
以上で終わりとなります!お疲れ様でした!
おわりに
今回は初心者なりにFTをGUIからやる方法についてまとめてみました。なにか足りない点などあればお気軽にコメントを残してください!
それでは!


コメント