

注意!設定を詰めるだけの話です!エッチな内容はありません!
こんにちは!秋ノ原窓也です。皆さん、普段息子のお世話はどのようにしていますか?私はよくgrokとせくしーなロールプレイをして遊んでいるのですがふと、こういう疑問が浮かんできました。
「これ以外のモデルでもせくしーなロールプレイできないものか、、、?しかもローカルで出来たらAPI関係なくね!?」
ということで今回は「Qwen3.5-35b-a3b」と一緒にエロチャットする方法を書いていきたいと思います。
実験環境
使用ソフトウェア LMStudio v0.4.7
使用モデル HauhauCS/Qwen3.5-35B-A3B-Uncensored-HauhauCS-Aggressive Q3_K_M
使用するソフトは最新版にしておきましょう。そうしないと設定に必要なパラメーターが出てきません。モデルはhauhaucsの無検閲モデルにしました。性能劣化がほぼないらしい。
使用マシン

cpu i5 8400 ram ddr4 32gb
RTX2060super & RX590 2GPU
ssd 256gb hdd500gb
PSU 750w win11home
です。それではやっていきましょう!
効率的な会話のための設定値
qwen3.5は同じことを何回も考えすぎてしまう癖があります。そのため、サクサク会話ができるように次の値を設定しましょう。これが公式の推奨する値です。
| temperture | top_p | top_k | min_p | presence_penalty | repitition_penalty |
| 0.7 | 0.95 | 20 | 0.0 | 1.5 | 1.0 |
出典 https://huggingface.co/Qwen/Qwen3.5-35B-A3B の下のほう
これは、qwen3.5が理想のパフォーマンスを出すためのパラメーターです。今回は会話タスク限定なので「instruct mode for general tasks」の値のみを書いています。ほかのタスク向けにも値が公開されているのでぜひ出典元を読んでみてください。
ここを、こう変更するといいです!
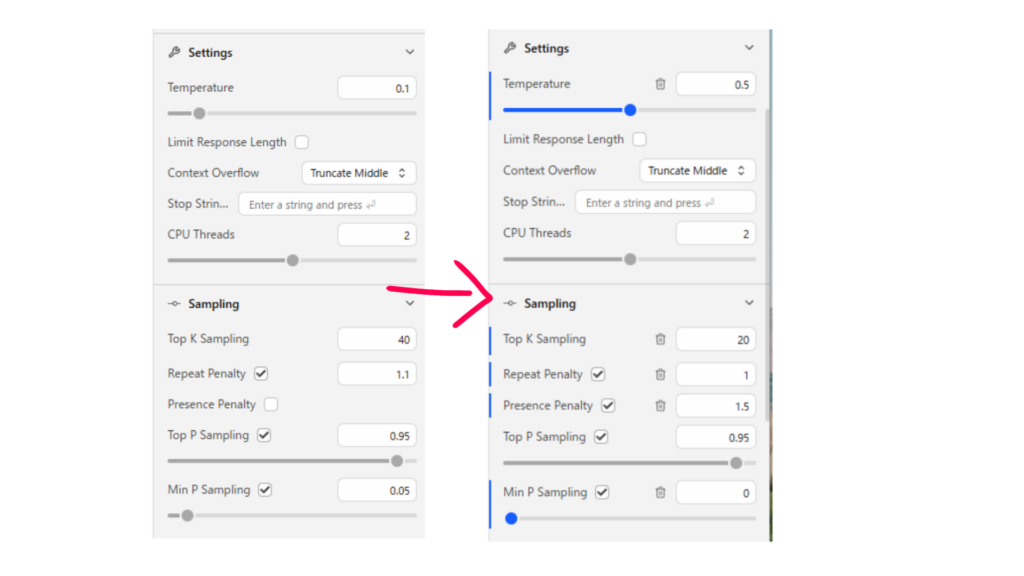
とは言いましたが、この設定難しいんですよね、、、
簡単に解説すると、tempertureは温度という概念で出力の内容がばらつくか、ばらつかなくなるかを調整します。0.7では少々高いようだったので0.5に設定しました。
presence penaltyは「値が高いほど出力に同じトークンが出てきにくくする設定」で、これで同じことを考えてループになるのを防ぎます。1.5だと出力がテンプレ化してしまうので1.4くらいにしておくといいかもしれません。
min_p、top_k=20はそれぞれ「もっともよく出てくるトークンの確率の値に対する、トークンの確率の値の最小割合が閾値になったら切り捨てる」「上位20トークンのみ扱い、ほかは切り捨てる」設定です。
top_Pは「確率の高いトークンの割合を足していき、その値が閾値になったらそれ以外のトークンを切り捨てる」設定です。値が大きいほど創造的になります。
では実際に効果を確かめてみましょう。
こちらがまず初期設定の様子

geminiとかほざいてますが蒸留に使われたんでしょう、、、。推論時間は約二分です。
次に設定を適用した時の様子ですが、
ここで注意点です。非検閲モデルだからなのかとても不安定になりやすいです。期待通りに動作することもありますが、出力の構造が崩れたりGPT3.5を自認したりします。ご自身の環境に合わせて設定を詰めましょう。
そして結果がこうです。

一気に推論時間が減って10秒になりましたね!大性交です!
まとめ
「よきエロチャットには、LLMの性質を理解して設定を詰めよう。OCみたいなもの。」
という感じでまとめようと思います。簡単にエッチな物が手に入るかと思ったら大間違いでしたね、、、。まあでも、強いモデルといい実験環境がそろったので思う存分これからナニを楽しみたいと思います!
それでは!
おまけ
こういう形で締めたものの、やはりgrokが一番強いということが判明しました、、、。ええ、、、


コメント