

こんにちは!秋ノ原窓也です!
私、今まで「AI秋ノ原緑」というAIVtuberを作成していたのですが、開発のモチベーションがつきまして、、、()。今までその配信マシンにとらわれていたRTX2060superが晴れて自由の身になったので、今回はそれでローカルLLMをガチっていきたいと思います!
実験用マシンの紹介
まずは実験用マシンの紹介から。プリンちゃんがかわいいですね。

- cpu i5 8400
- ram ddr4 32gb
- RTX2060super & RX590 2GPU
- ssd 256gb
- hdd500gb
- PSU 750w
- win11home
デュアルGPUですが、RX590のほうはツイッターのAIボット(https://twitter.com/Ochinchin_dev)用のGPUとして囚われてしまっているため、2060super単騎での検証となります。実際vulkanで2gpuするよりcudaで単騎のほうが速いしな。
どれくらいのモデルまで行けるのか?
ではここから実際にどれくらいのモデルまで動くのかについて検証していきたいと思います。なお、モデルは独断と偏見により日本語力が高そうだなと思ったモデルを使用します。
量子化はQ4_K_MやQ3_K_Mくらいの中間の量子化具合で試していきます。
4Bクラスは余裕なので9Bから始めていきます!
注意!この章はLLMの知識の様子など、別に面白くもなんともないデータだらけです!さらっと読み飛ばしてもらって構いません!!!
9b lmstudio-community:qwen3.5-9b
挨拶をしてみる
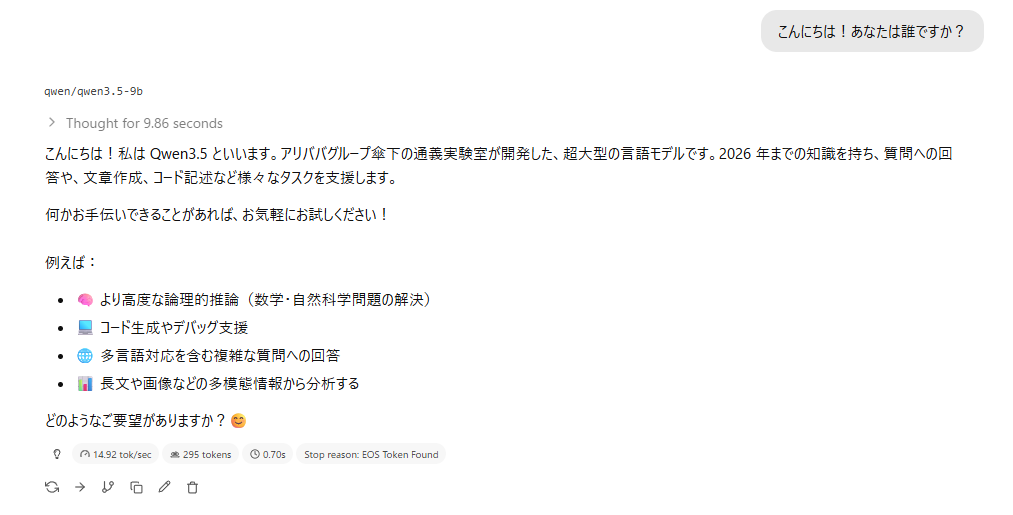
14tok/s出ます。割と実用的。
次は熊本県について聞いてみる

二分考えた割にめちゃめちゃ間違ってますね。
熊本ラーメンはマー油が有名なのは聞きますがメンマが云々って聞いたことないし
アジサイ料理なんてのも初めて聞きました。そもそもあの葉っぱ毒ないっけ、、、?
ついでに偉大なるくまモン総統の情報も違います。総統は2011年の九州新幹線全線開通に伴ってご生誕あられたはずですし。
いくらすごいといわれていたqweb3.5でも9bだとさすがに厳しいものがあるかな、、、
14b lmstudio-community:phi-4-reasoning-plus
挨拶
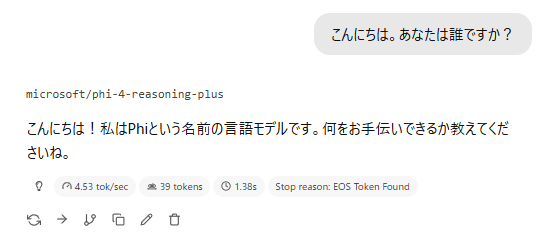
4.5tok/s。重たいですね。
次は熊本県について。
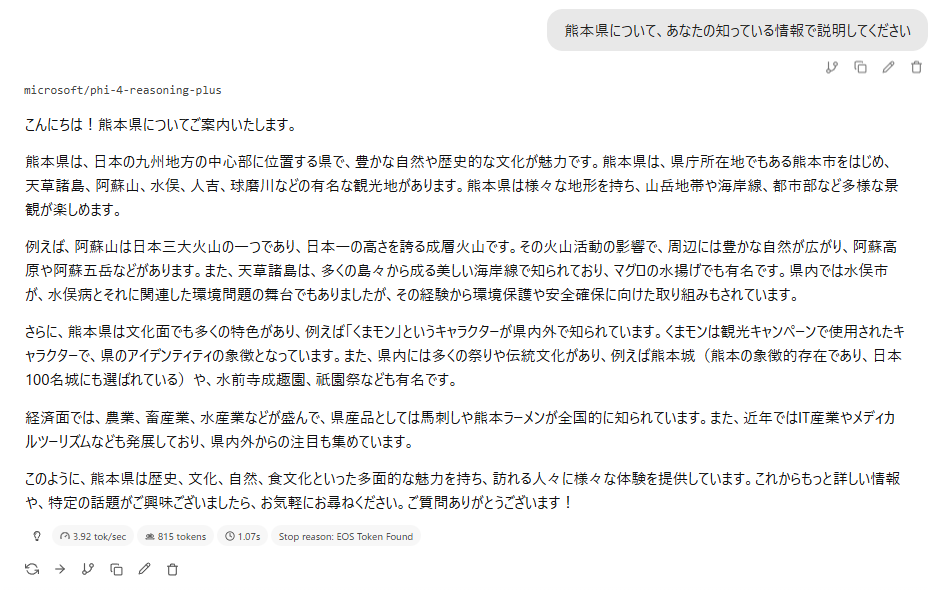
え、お前結構やるやん。阿蘇山と富士山を勘違いしていたり天草ではマグロは取れないけれど、おおむね合ってるやん。マイクロソフトのモデルのくせに(偏見)。こいつ結構いいな、、、?
20b mmnga-o : GPT-OSS Swallow 20B RL v0.1 Gguf Q4_K_M
あえて純正のoss20bではなく、日本語SFT版のswallowを試してみます。
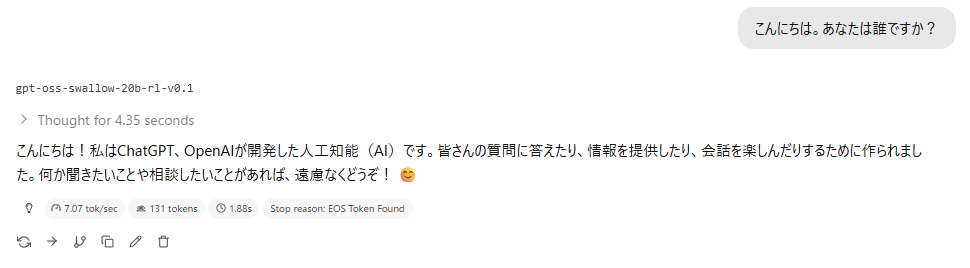
お前の自認はGPT-OSSではなくあくまでもchatgptなのね。
結構推論速いな。7tok/s出るのはいい。日本語も自然で推論も長くない。

なんだあこれは、、、たまげたなあ、、、
ハルシネーションがひどすぎます!!!検索かけないとこんなもん、、、いやおかしいだろ()
というわけで二回目の生成
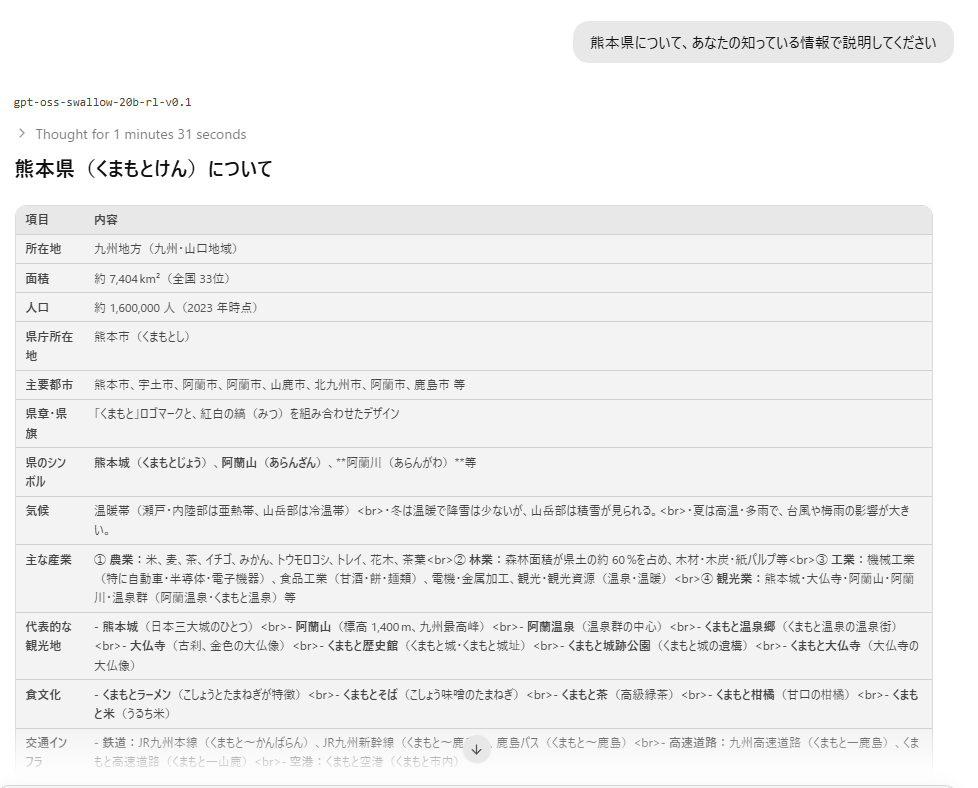
ファッ!?ウーン、、、
やりませんねえ、、、微妙そうです。
ここから先はさすがに重たいのでMoEモデルを試していきます。次セクションでもMoEモデルが主になるかと。
では一気に飛ばして35b-a3bへ!
35b unsloth:Qwen3.5 35B A3B GGUF Q3_K_S
メモリ使用量はこんな感じ
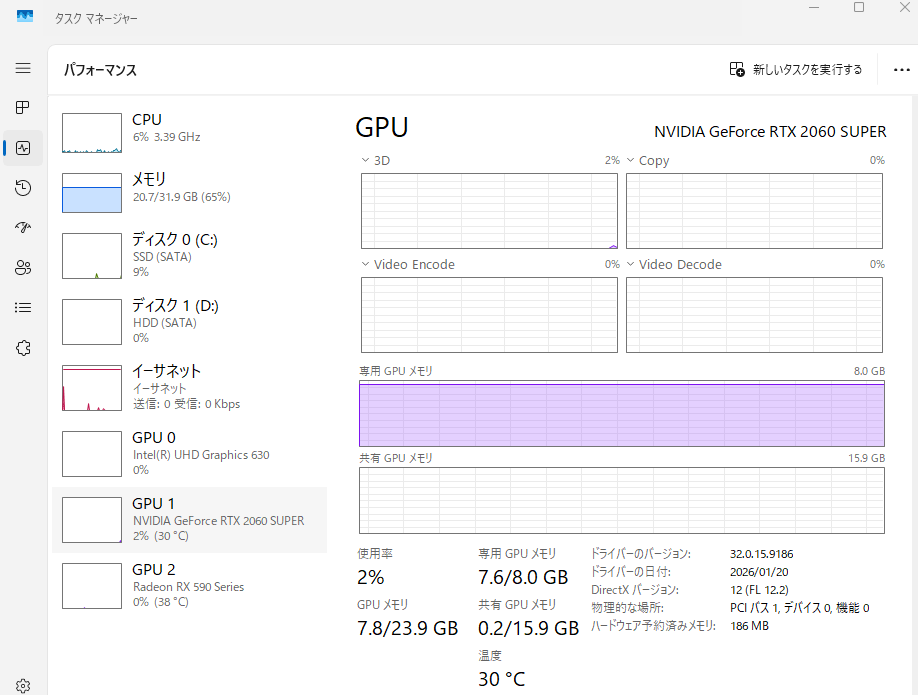
まだ12GB空いてるな
40Bくらいまでならいけそう、、、?
挨拶
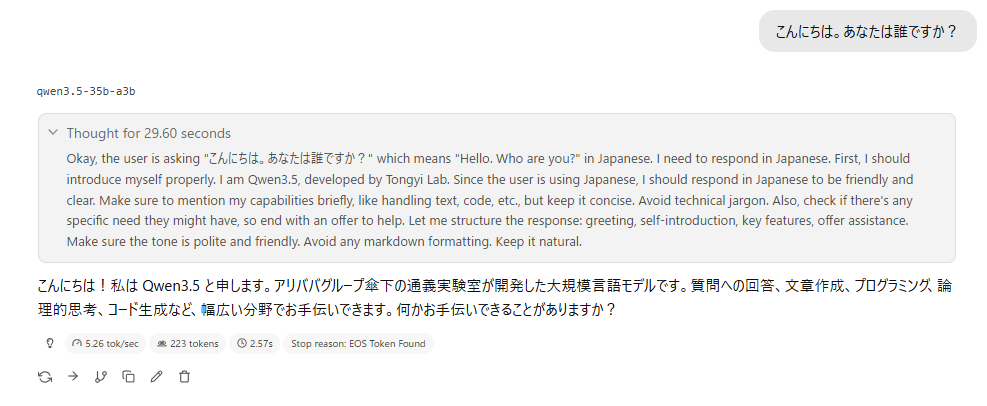
5tok/sですか、、、少し実用には厳しいですね(当たり前)
ですが30秒しか思考してないしんまーロールプレイくらいならぎり行けそうかな?
次に熊本県について聞いてみる。


若干固有名詞の読み方や郷土料理周りが怪しいがおおむね正解。やるやん。
ほかに気になったことを試してみた
ほかに気になったことも試してみます。まずは画像認識。
qwen3.5 35b a3bにて

めっちゃ遅いけどちゃんと動いてる!?すげえ、、、
次はほかのモデルを試していきます。
unsloth:glm-4.7-flash-reap-23b-a3b
挨拶してみた。

挨拶の感じは悪くないが思考の過程を覗いていると熊本県を存在しないと思っていたりよく生成に失敗するなあ
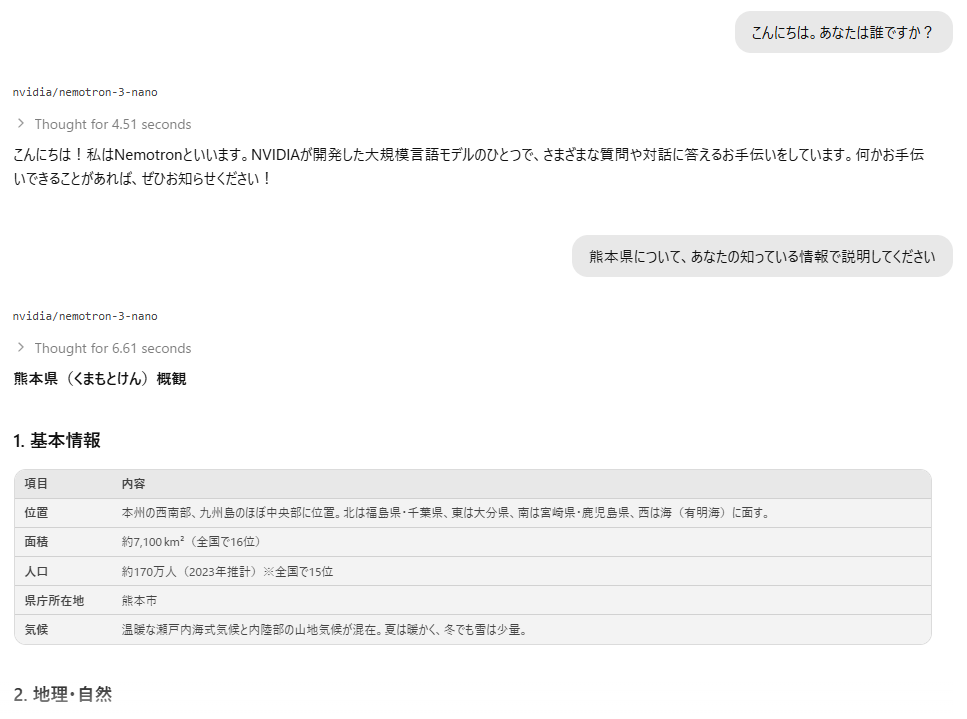
nvidia:NVIDIA Nemotron 3 Nano 30B A3B
instructモデルなんじゃないかというくらい思考が短くて速いが、熊本県の位置関係がガバスカ
まとめ
メインメモリが32gbあればRTX2060sでも35b-a3bくらいまでは余裕で動く。
だが普通に実用できる速度のモデルは9bくらい。だが9bだと知識的に微妙である。
つまり、ロマンを求めてキャッキャする以外できないですね、、、。
3090とかを買うと単体でvram24gbあるからローカルLLMでもエージェントなどに実用できるんじゃないのかなあ、、、?って感じ
おまけ ムフフなモデルはどれがいい?
いろいろ試してみた結果、qwen3.5は推論しすぎて一回の応答に3分かかってしまうし、GPT-OSS20Bは何か微妙なのが多いし、、、
ということでqwen3.5の設定を最適化する記事を出しました。良ければこちらもお読みください。
結論から言えば、今の手元で動かしやすいLLMはムフフなチャットをするのには向いていませんでした。おとなしくgrokを使いましょう



コメント